
Künstliche Intelligenz zur Vorhersage der Photovoltaikleistung

06:00 Uhr
Emmas Wecker klingelt. Sie wacht langsam auf, streckt sich und nimmt ihr Handy vom Nachttisch. Sie schaut aber nicht, ob ihr letztes Foto in den sozialen Medien viele Likes bekommen hat, sondern interessiert sich für die Wettervorhersage für heute: Es soll ein schöner sonniger Tag werden. Als nächstes schaut sie auf ihre Energiemanagement-App, die ihr bestätigt, dass die Photovoltaik-Anlage auf ihrem Dach wegen des sonnigen Wetters heute viel Energie erzeugen wird. In diesem Moment erinnert sie sich an den Tag vor zwei Jahren, als die PV-Anlage auf ihrem Dach installiert wurde. Damals ist für sie ein großer Traum in Erfüllung gegangen: Den Großteil der notwendigen elektrischen Energie für den eigenen Haushalt umweltfreundlich und vor Ort zu erzeugen. Emma fragt sich, wie die App auf ihrem Handy wohl die Photovoltaik-Vorhersage berechnet, schließlich hat sie damals keine Informationen über die Anlage eingeben müssen. Lernt die App das etwa alles selbst? Und wenn ja, wie?
Wie haben wir angefangen?
Seit drei Jahren arbeitet die Arbeitsgruppe Energiemanagement am DLR-Institut für Vernetzte Energiesysteme in Oldenburg an einem Verfahren zur direkten Vorhersage der PV-Leistung mit Hilfe des maschinellen Lernens beziehungsweise der künstlichen Intelligenz. Besonders ausführlich wurde dieses Thema im Forschungsprojekt EMGIMO untersucht. Die allgemeinen Problemstellungen und Ziele dieses Projektes könnt ihr im ersten Teil dieses Blogs nachlesen.
In diesem Blogbeitrag erzählen wir euch, wieso die Vorhersage der PV-Leistung so wichtig für das Projekt ist und wie diese Vorhersage erstellt wurde. Wie im vorangegangenen Blog geschildert, wurde eine PV-Anlage mit einer Leistung von 99,9 kWp auf dem Dach einer Mehr-Mieter-Gewerbeimmobilie in München installiert. Damit ihr ein Gefühl für die Größe dieser PV-Anlage bekommt, geben wir euch einen Vergleichswert: Eine PV-Anlage dieser Größe könnte so viel elektrische Energie pro Jahr erzeugen, wie etwa 29 Haushalte mit durchschnittlich vier Personen bilanziell über das ganze Jahr benötigen.
Allerdings darf der Gebäudebetreiber dieser Mehr-Mieter-Gewerbeimmobilie die von der PV-Anlage erzeugte Energie aus rechtlichen Gründen nur für die Haustechnik im Gebäude nutzen, also zum Beispiel für die Flurbeleuchtung, den Aufzug oder die Klimaanlage. Die Mieter des Gebäudes darf er aber nicht dazu verpflichten, ihm den Strom aus der PV-Anlage abzukaufen. Diese große PV-Anlage erzeugte im Jahr 2019 bilanziell 39 Prozent mehr Energie, als für die Haustechnik notwendig war. Damit mehr PV-Strom direkt vor Ort verbraucht wird, wurden sechs Ladesäulen für Elektroautos in der Tiefgarage des Gebäudes installiert. Somit können die Personen, die in diesem Gebäude arbeiten, ihre privaten oder gewerblichen Elektrofahrzeuge hier umweltfreundlich mit Solarstrom laden.

Der PV-Strom muss intelligent zwischen Haustechnik und Ladestationen für E-Autos verteilt werden, ohne die maximal zulässige Leistungsgrenze des Gebäudes zu überschreiten. Zu diesem Zweck muss der EMGIMO-Gebäudebetreiber wissen, wie viel Energie die PV-Anlage in den nächsten 24 Stunden voraussichtlich erzeugen wird. Also benötigt er eine Vorhersage, um die Ladevorgänge für die E-Autos über den Tag intelligent und umweltfreundlich zu planen.
Wie gesagt: Die PV-Anlage erzeugt mehr Energie, als innerhalb des EMGIMO-Gebäudes für den Eigenverbrauch (der Anteil, der im eigenen Haus verbraucht wird und nicht in das öffentliche Netz eingespeist wird) benötigt wird. Der überschüssige Strom, beziehungsweise der Anteil, der zu diesem Zeitpunkt lokal nicht verbraucht werden kann, wird zu einem im Erneuerbare-Energien-Gesetz (EEG) festgelegten Preis in das öffentliche Netz eingespeist. Allerdings sind diese Vergütung und der Anteil des Eigenverbrauchs so gering, dass es sich nicht rechnen würde, eine PV-Leistungsvorhersage regelmäßig als kostenaufwendige Dienstleistung einzukaufen.
Vor diesem Hintergrund war es unser Ziel, ein möglichst kostengünstiges, konfigurationsarmes und selbstlernendes Vorhersagetool zu entwickeln. Unter "konfigurationsarm" versteht man hier, dass das Vorhersagetool kein Vorwissen über die PV-Anlage braucht, beziehungsweise keine technischen Informationen (installierte Leistung, Ausrichtung, Neigungswinkel der Module) über die PV-Anlage angegeben werden müssen – quasi eine Plug-and-Play-Lösung. "Selbstlernend" bedeutet, dass das Vorhersagetool Veränderungen der Wetterbedingungen (zum Beispiel eine Schneeschicht auf den PV-Modulen), Fehler (zum Beispiel ein defektes PV-Modul) und andere Ereignisse automatisch erkennt und sie bei der Prognoseerstellung berücksichtigt. Möglich wird der kostengünstige Betrieb des PV-Vorhersageverfahrens, wenn dieses auf frei verfügbaren und kostenlosen Daten basiert.
Aber wieso benötigt das Vorhersageverfahren die Daten und welche Daten sind dafür notwendig? Das erzählen wir euch gleich. Erstmal zurück zu Emma:
07:00 Uhr
Emma lädt die Waschmaschine voll – nicht, weil sie jetzt dringend die saubere Wäsche braucht – sondern weil das Home-Energiemanagementsystem sie informierte, dass sie später mit dem PV-Strom günstig waschen kann. Somit kann der Eigenverbrauchsanteil der PV-Anlage erhöht werden. Die ersten Gedanken über Eigenverbrauchsoptimierung kamen bei Emma auf, nachdem die PV-Anlage zwei bis drei Monate in Betrieb war. Da sie und ihr Freund berufstätig sind, verbringen sie fast den ganzen Tag bei der Arbeit, während die Sonne auf die PV-Module scheint und die PV-Anlage Energie erzeugt. In den ersten Monaten des Betriebs bemerkten sie, dass viel mehr Energie von der PV-Anlage ins Netz eingespeist wurde, als bei ihnen zu Hause verbraucht wurde. Emma wollte den eigenen PV-Strom aber gerne selbst nutzen und nicht nur ins Netz einspeisen. Deshalb erkundigte sie sich, welche Lösungen es dafür gibt. Da war zum Beispiel die Möglichkeit, sich einen Energiespeicher, einen sogenannten Heimspeicher, zu beschaffen. Dieser speichert die überschüssige elektrische Energie von der PV-Dachanlage zwischen bis sie abends benötigt wird. Noch besser gefiel Emma aber die Idee eines intelligenten, vorhersagebasierten Energiemanagementsystems. Dieses prognostiziert den täglichen Energieertrag der PV-Anlage und berücksichtigt diese Vorhersage bei der Planung des Betriebs von elektrischen Haushaltsgeräten. Befolgt man diese Empfehlungen, dann lässt sich der Eigenverbrauchsanteil ganz einfach optimieren.
Zurück zu unserer wissenschaftlichen Arbeit, schließlich sind wir euch noch eine Antwort schuldig:
Warum KI?
Ein Vorhersagetool, das kostengünstig, konfigurationsarm und selbstlernend arbeiten soll, lässt sich am besten mit Methoden der künstlichen Intelligenz (KI) realisieren. Falls ihr euch jetzt fragt: "Warum eigentlich KI für eine PV-Vorhersage?" – Dafür sprechen folgende drei Punkte, die aus den Anforderungen zur PV-Vorhersage abgeleitet wurden:
1. Da die Energieerzeugung der PV-Anlagen von Wetterbedingungen abhängt, braucht man eine Wetterprognose (im besten Fall eine Solar-Strahlungsprognose), um eine PV-Leistung vorherzusagen. Diese Daten sollten frei verfügbar sein, damit ein kostengünstiger Betrieb des Vorhersageverfahrens gewährleistet werden kann. Für das EMGIMO-Projekt haben wir uns für den Online-Wetterdienst OpenWeatherMap entschieden, weil dort sowohl die aktuellen meteorologischen Messwerte als auch die Wettervorhersage für verschiedene Standorte weltweit angeboten werden. Obwohl dieser Dienst viele wichtige meteorologische Parameter wie Lufttemperatur, Luftdruck, Windgeschwindigkeit, Niederschlagstyp, Bewölkungsfaktor usw. zur Verfügung stellt, übermittelt er leider keine Werte der Solarstrahlung ("Global Horizontal Irradiance",kurz GHI). Da PV-Module die Energie der Sonnenstrahlen direkt in elektrische Energie umwandeln, ist GHI einer der wichtigsten Parameter im Bereich der Solarenergieforschung. Somit standen wir vor einer Herausforderung: Wie können wir ohne dieses Wissen über die Globalstrahlung die PV-Leistung in unserem Vorhersagetool prognostizieren?
2. Um konfigurationsarm zu funktionieren, soll das von uns entwickelte Vorhersagetool ohne manuelle Eingabe technischer Informationen der PV-Anlage (installierte Leistung, Ausrichtung, Neigungswinkel der Module) auskommen. Allerdings stehen jedem Anlagenbetreiber die Leistungswerte seiner PV-Anlage, also die erzeugte Leistung in Watt, kostenlos zur Verfügung. Wir haben uns gefragt, ob es möglich ist, eine PV-Vorhersage allein aus den gemessenen Leistungswerten und ohne technische Daten der Anlage zu erstellen.
3. Es gibt zwei Hauptverfahren, um die Leistung der PV-Anlage zu prognostizieren: physikalische Modelle und Algorithmen des maschinellen Lernens. Das physikalische Modell benötigt die Solarstrahlungswerte für den Standort der PV-Anlage sowie die technischen Daten dieser PV-Anlage, vor allem die installierte Leistung und Ausrichtung. Daher mussten wir das physikalische Modell ausschließen. Aus diesen Gründen entschieden wir uns für die Algorithmen des maschinellen Lernens, beziehungsweise KI, um die PV-Vorhersage für das EMGIMO-Projekt zu erstellen. Wir haben dafür verschiedene Algorithmen des maschinellen Lernens untersucht und uns letztendlich für sogenannte künstliche neuronale Netze (KNN) entschieden. Die Funktionsweise der KNN ist vom menschlichen Gehirn inspiriert: Ähnlich wie das menschliche Nervensystem besteht auch ein KNN aus vielen Neuronen beziehungsweise Knoten, die miteinander verbunden sind. Das einfachste KNN besteht aus einem Eingangsneuron, einem verborgenen Neuron und einem Ausgangsneuron. Die Information läuft vom Eingang über das verborgene Neuron bis zum Ausgang. Jedes Neuron bekommt die Information von den vorherigen Neuronen, modifiziert sie und leitet an die nächsten Neuronen weiter.

Die Verbindungen zwischen Neuronen können unterschiedlich stark sein. Diese Verbindungsstärke wird als Gewicht bezeichnet. Je größer das Gewicht zwischen den Neuronen ist, desto stärker sind diese mit-einander verbunden und desto mehr Information wird von einem Neuron an das nächste weitergegeben. Die Gewichte passen sich mehrfach automatisch an, sodass das Netz mit jeder Anpassung präzisere Ergebnisse liefern kann. Den Prozess der Anpassung der Gewichte nennen wir "Training". Das Trainieren von KNN beinhaltet viele komplexe interne Prozesse, die für uns Menschen kaum nachvollziehbar sind. Wegen dieser mangelnden Nachvollziehbarkeit sowie der Intransparenz des Trainingsprozesses werden KNN oft als Black Box bezeichnet.
Die KNN verfügen über verschiedene Strukturen. Auf Basis unserer Bedingungen und Problemstellungen haben wir uns für eine besondere Struktur des künstlichen neuronalen Netzes, nämlich das sogenannte Long Short-Term Memory (LSTM) entschieden.
Womit "füttern" wir unser KI-Vorhersagemodel?
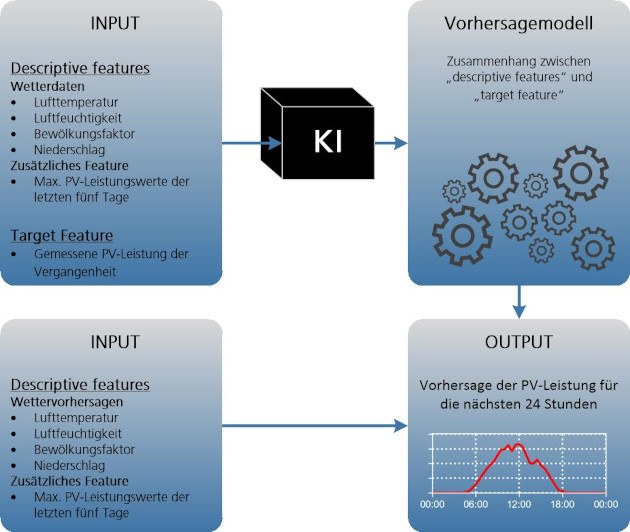
Oben haben wir beschrieben, dass alle KNN Eingangsinformationen, also "Futter", brauchen, um die zu bearbeiten und ein Ergebnis zu liefern – in unserem Fall ist das Ergebnis die Vorhersage der PV-Leistung für die nächsten 24 Stunden. Die Eingangsinformationen für unser Vorhersagemodell sind die frei verfügbaren Wetterdaten, welche Lufttemperatur, Luftfeuchtigkeit, Bewölkungsfaktor und Niederschlag einschließen. Diese beinhalten jedoch keine Globalstrahlungswerte. Deswegen haben wir entschieden, ein zusätzliches Input-Feature aus den vorhandenen gemessenen Leistungswerten der PV-Anlage zu generieren. Die PV-Leistungswerte sind direkt von der Solarstrahlung, die auf die PV-Module fällt, abhängig. Dieser direkte Zusammenhang zwischen der Solarstrahlung, beziehungsweise GHI, und der PV-Leistung ist auf dem unteren Bild deutlich zu sehen. Auf den ersten Blick erkennt man, dass sich die Leistung der PV-Anlage (blauer Bereich unten) erhöht, wenn die Solarstrahlung (gelber Bereich oben) steigt und mit dem Sonnenuntergang auch die PV-Leistung wieder sinkt.

Um das zusätzliche Feature für das Vorhersageverfahren zu generieren, werden die maximalen Werte der gemessenen PV-Leistung der letzten fünf Tage für jeden Zeitpunkt verwendet. Aus diesen Werten wird eine Kurve gebildet, die im Grunde genommen eine maximal zulässige Leistungsgrenze für die PV-Anlage darstellt. Das generierte Feature hilft uns auf der einen Seite dabei, die maximal erzeugte Leistung der PV-Anlage nicht zu überschreiten und damit nicht unrealistisch hohe Prognosen der PV-Leistung zu erstellen. Auf der anderen Seite lernt das Vorhersagetool die Zeiten von Sonnenauf- und -untergang, die sich jeden Tag ein wenig vom Vortag unterscheiden. Des Weiteren zeigt dieses Feature uns auch die wetterbedingten Veränderungen oder technische Defekte der PV-Anlage.
Dieser zusätzlich generierte Parameter sowie die frei verfügbaren Wetterdaten werden als Input-Daten, beziehungsweise die Daten, die in das KI-Model hineinfließen, verwendet. In der KI-Welt werden sie oft als "descriptive features" bezeichnet. Zusammen mit diesen Daten werden auch die gemessenen PV-Leistungswerte der vergangenen Tage, die wiederum "target feature" genannt werden, in die Black Box geleitet.
Aus den historischen Wetterdaten, den berechneten Werten des zusätzlichen Parameters und den historischen PV-Leistungsmesswerten wurde ein Trainingsdatensatz erstellt. Dieser wurde verwendet, um das Vorhersagemodell zu trainieren. Dabei versucht die KI einen Zusammenhang zwischen "descriptive features" und "target feature" zu erlernen und möglichst auch auf neue Situationen anzuwenden. In weiteren Schritten verwendet das Modell diese Zusammenhänge, um eine PV-Leistungskurve für die nächsten 24 Stunden auf Basis der vorhandenen Wetterprognose zu erstellen. Diese prognostizierte PV-Leistungskurve ist der Output und somit das Ergebnis des gesamten Vorhersageprozesses.
Doch bevor der Trainingsprozess innerhalb der KI-Black Box überhaupt beginnen kann, müssen die Inputdaten dafür sorgfältig vorbereitet werden. Diese Datenvorbereitung beinhaltet unterschiedliche Maßnahmen wie zum Beispiel das Finden und Ersetzen fehlender oder falscher Werte, das Anpassen der zeitlichen Auflösung von Daten sowie das Normalisieren aller Werte.
07:30 Uhr
Emma steigt in ihr E-Auto und fährt zu Arbeit. Das Auto ist zwar nicht vollgeladen, aber es hat genug Energie in der Batterie, damit Emma sicher zur Arbeit kommt. Das Gebäude, in dem sie arbeitet, ist auch mit einer PV-Anlage und dem intelligenten Energiemanagementsystem ausgestattet. Sie weiß, dass sie ihr E-Auto bei der Arbeit mit dem Solarstrom intelligent, umweltfreundlich und zu günstigen Konditionen für Mitarbeiterinnen und Mitarbeiter laden kann.
Wie sieht die PV-Vorhersage denn aus?
Wir haben euch gezeigt, wie das Vorhersageverfahren mit KI aufgebaut ist und welche Inputdaten benötigt werden. Doch auch für die Ergebnisse des Verfahrens mussten wir uns mit einigen Fragen beschäftigen. Die erste Frage war, wie wir die Qualität der erstellten Prognosen bewerten können. Der britische Wissenschaftler George E.P. Box sagte einmal: „All models are wrong, but some are useful.“ Frei interpretiert heißt das, kein KI-Modell kann eine 100 Prozent genaue Prognose liefern. Die Prognose kann die realen Werte entweder über- oder unterschätzen. Diese Prognosefehler können anhand verschiedener Fehlermaße dargestellt werden. Für unsere Studie haben wir die Differenz zwischen den vorhergesagten und realen Leistungswerten der PV-Anlage betrachtet, um die Genauigkeit der Prognose zu messen.
Die zweite Frage, die uns beschäftigt hat, war die Größe des Trainingsdatensatzes, beziehungsweise mit wie vielen Tagen aus der Vergangenheit das Vorhersagemodell trainiert werden soll. Um diese Frage zu beantworten, haben wir verschiedene Datensätze getestet, darunter Input-Datensätze mit den letzten 7, 14, 30 und 90 Tagen. Wir haben alle Datensätze zum Trainieren des Modells und zur Erstellung von PV-Leistungsvorhersagen genutzt. Anschließend haben wir die Prognosefehler für alle Datensätze berechnet und miteinander verglichen. Nach allen Simulationen haben wir die Datensatzgröße von 90 Tagen ausgewählt, da das Training mit diesem Datensatz zur Senkung von Prognosefehlern führte. Die Begründung für den größten Datensatz liegt vermutlich darin, dass das KI-Modell mehr Zusammenhänge zwischen den Wetterdaten, dem zusätzlichen Parameter und den PV-Leistungsmesswerten erlernen kann, wenn der Trainingsdatensatz mehr Daten enthält. Mit anderen Worten sammelt dieses Vorhersagemodell mehr Erfahrung, um auf Basis von aktuellen Wetterprognosen eine genauere PV-Vorhersage zu erstellen.
Unsere dritte Frage war, wie sich die Trainingsdauer und die Prognosegenauigkeit ändern, wenn wir unser Vorhersagemodell mit den GHI-Werten trainieren. Dafür haben unsere Kollegen aus der Arbeitsgruppe Energiemeteorologie die historischen Messwerte sowie die Vorhersagen der Globalstrahlung zur Verfügung gestellt. Wie zuvor nutzten wir diese neuen Daten, um den Algorithmus zu trainieren und die PV-Leistung vorherzusagen. Dazu seht ihr unten zwei Bilder mit den gemessenen Werten der PV-Leistung (gelbe Bereiche) für zwei unterschiedliche Tage im Juni 2019. Für diese Tage haben wir zwei Vorhersagen der PV-Leistung erstellt: mit den frei verfügbaren Wetterdaten (rote Kurve) und mit den Globalstrahlungsdaten (hellblaue Kurve).
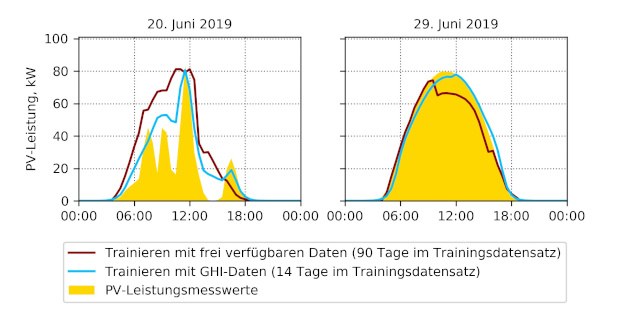
Unsere Ergebnisse zeigten, dass wir viel mehr frei verfügbare Wetterdaten zum Trainieren benötigen, also mehr Tage in die Vergangenheit gehen müssen, im Vergleich zu den GHI-Daten, um das bestmögliche Ergebnis zu erhalten. Obwohl die verwendeten frei verfügbaren Wetterdaten keine Solarstrahlungswerte enthalten und das von uns entwickelte Vorhersageverfahren keine technischen Informationen über die PV-Anlage erhält, kann es trotzdem aussagekräftige Prognosen der PV-Leistung für die nächsten 24 Stunden erstellen, wie in diesem Beispiel der Abfall der PV-Leistung am Nachmittag des 20. Juni 2019 vorhergesagt wurde.
Die Verwendung von Solarstrahlungswerten als Inputdaten für das entwickelte Vorhersagetool führt zu präziseren Prognosen der PV-Leistung. Des Weiteren kann der Trainingsdatensatz die Strahlungsdaten ausschließlich von den letzten 14 Tagen enthalten, um eine genauere Vorhersage zu erstellen. Das führt auch dazu, dass die Rechenzeit für den Trainingsprozess stark reduziert werden kann. Derartige hoch-präzise Vorhersagen der volatilen Energieerzeugung von erneuerbaren Energien werden vor allem bei den Netzbetreibern benötigt, weil sie die Stabilität des ganzen Netzes sicherstellen müssen. Das PV-Vorhersagetool, welches wir für das Projekt EMGIMO entwickelt haben, wurde von Anfang an für das lokale Gebäude-Energiemanagement konzipiert. Die Genauigkeit des entwickelten Vorhersageverfahrens mit den frei verfügbaren Wetterdaten ist ausreichend, um den Betrieb von flexiblen elektrischen Anlagen lokal zu planen und zu steuern, wie zum Beispiel die Ladung von mehreren Elektroautos über den Tag zu verteilen.
Wenn ihr mehr über das entwickelte Vorhersageverfahren sowie die Ergebnisse dieses Verfahrens wissen wollt, könnt ihr in unserem Paper „A Machine Learning Approach to Low-Cost Photovoltaic Power Prediction Based on Publicly Available Weather Reports“ mehr darüber erfahren.
08:00 Uhr
Emma kommt bei der Arbeit an und schließt ihr E-Auto an die Ladesäule in der Tiefgarage an.
Im nächsten Beitrag erzählen wir euch, wie der Energieverbrauch für ein Gebäude vorhergesagt werden kann und wie diese Vorhersage das Laden von E-Autos unterstützen könnte.
Tags: