
Methods

{kind=link}


The Visual System
The task of vision for a service robot is to deliver an interpretation of the scene that contains both geometric and semantic information. In other words, the Robutler has to know where objects are placed and what can be done with them. Clearly, the semantics of an object is not generally conceivable from vision alone. This kind of knowledge can presently be only attached to object models in a database. It is thus natural for a service robot to work with an a priori known set of objects.
We use a three-camera system (Digiclops, Point Grey Research Inc.) to perform stereo processing with a horizontal and a vertical stereo pair (baseline 10 cm). Each image has a resolution of 640x480 pixels. The objects we are dealing with, bottles and glasses are challenging for the visual system. The reason is that visual data of transparent objects are generally more ambiguous than of opaque, colored or textured objects. As a result, mainly surface creases and depth discontinuities contribute to stereo processing. The output thus is a sparse representation of the scene by rather few 3D-data points, outlining the objects on the table.
The object models used for scene analysis are derived, in a learning phase, from empirically sampled histograms of the stereo data that are produced by the objects of interest. During scene analysis, search and optimization of the match of all object models to the stereo data across all possible pose parameters is efficiently implemented by a fuzzy variant of the generalized Hough transform. We have found that our method can cope with challenging objects such as glasses under partial occlusion and over large variations of lighting (daylight, fluorescent light, and spotlight). This kind of robustness is required for unconstrained real-world scenarios of service robotics.
These three images show the Robutler during analysis of a tabletop scene, just before starting to act. The scene features a bottle and two wine glasses. The 3D-point data obtained from stereo processing and the result of scene analysis are respectively overlaid on the second and third image. Note the large amount of noise and background data that arise as artifacts from stereo processing under such difficult conditions (transparent objects). In the result graph, the three peaks represent the distribution of evidence across the table for the different objects. The bottle and the two glasses are correctly located and identified.
In future applications of service robots, it will also be necessary to manipulate objects which are a priori not known. For an unknown object, the best we can do is to extract a description of its surface that is sufficiently informative for a grasp to be inferred. We currently follow two different strategies: first, by sampling surface normals from the stereo-data points; second, by fitting generalized cylinders to the stereo data.

The Task-Oriented Programming Interface (AOP)
For the flexible programming of manipulation tasks the same system is used for Robutler as for our Telerobotic and Space Application Experiments. The manipulation tasks are combined from so called Elemental Operations in a Graphical User Interface. These Elemental Operations combine sensor information, control strategies and basic Cartesian or joint angle movements provided by the system setup. The reaching and grasping of a bottle for example might consist of these basic operations:
- Move the Hand Cartesian in a grasp position relatively to the object (object pose known from scene analysis or by distance sensor, dependent on system setup)
- Drive the fingers in a predefined grasp shape (joint angles) suitable for the object
- Grasp the bottle with fingers impedance controlled and the stiffness adjusted to robust grasp the bottle
Such a list of Elemental Operations forms a more or less complex task that can be executed by a non expert user. For the Robutler System all defined operations have been brought to simple and intuitive icons to command the system with some mouse clicks or a touch screen.
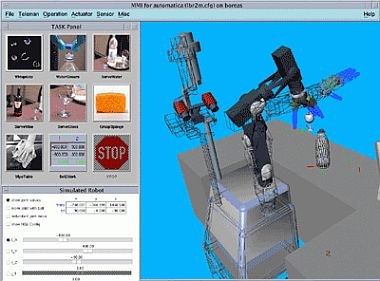
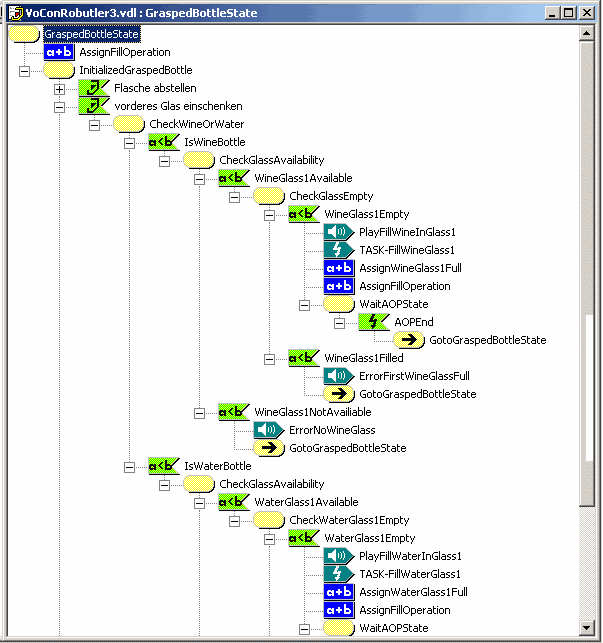
The simple and flexible task interface allows easy integration of different high level man machine interfaces. For the demonstration on the Automatica Trade Show the connection to a commercial speech recognition system (VOCON, ScanSoft) has been implemented. A dialog containing all task level commands has been designed graphically. As we provided the world model update information of the scene analysis component not only to the task programming environment but also to the dialog manager of the speech recognition the system was aware of the objects available. Therefore the system neglected impossible. For example it told the user that it was not possible to serve wine if there was no wine bottle on the table. To give intuitive feedback the dialog contained voice messages to confirm actions or report errors to the user.
A desirable extension for the future use of the speech recognition is the integration of a system to automatically generate the finite state dialog from the task operation list and the data from the object recognition.
{kind=link}