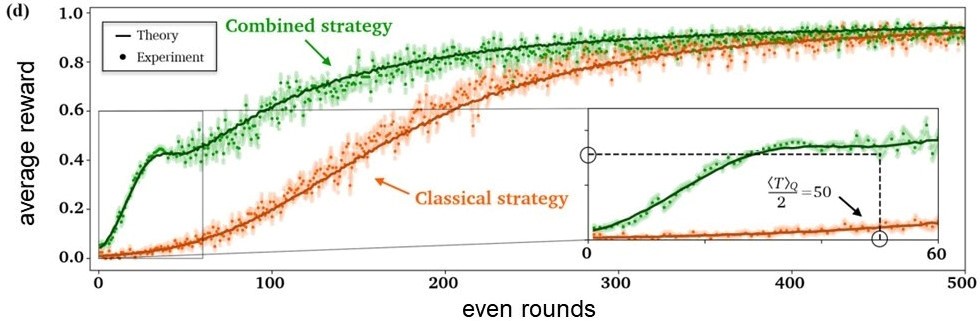
Ein quantenmechanischer Agent (combined strategy) erhält im Durchschnitt mehr Belohnungen (average reward) als ein rein klassischer Agent (classical strategy) und lernt dadurch schneller.
Wir Menschen lernen ständig Neues indem wir verschiedene Dinge ausprobieren und aus den so gemachten Erfahrungen lernen. Auch Maschinen, sogenannte Agenten, können lernen, bestimmte Probleme zu lösen, indem sie verstärkt Aktionen durchführen, für welche sie früher bereits Belohnungen erhalten haben. Dies ist das Prinzip des bestärkenden Lernens. Häufig dauert es aber recht lange, bevor ein Agent erste Aktionen findet, welche zu einer Belohnung führen. Dadurch dauert auch das Lernen lange. Mit Hilfe von Quantenalgorithmen kann diese Suche beschleunigt werden.
Zusammen mit den Universitäten Wien, Innsbruck und Leiden sowie dem MIT konnten wir diese Beschleunigung in einem Demonstrationsexperiment zeigen. Hierbei konnte ein abstraktes Problem mit Hilfe von Quantenalgorithmen bereits nach durchschnittlich 100 Versuchen gelöst werden. Ein entsprechender klassischer Agent brauchte mit durchschnittlich 266 Versuchen mehr als doppelt so lange.
Um reale Probleme mit bestärkendem Lernen und Quantenalgorithmen zu lösen, sind aber noch viele Herausforderungen zu meistern. Zum einem können mit den bereits existierenden Quantencomputern zurzeit nur sehr einfache Quantenalgorithmen implementiert werden. Zum anderen müssen wir für die verschiedenen Probleme Lernstrategien entwickeln, welche die grundlegenden Prinzipien der Quantenmechanik, wie den Welle-Teilchen-Dualismus, berücksichtigen. Ähnlich wie eine Wasserwelle, welche sich in allen Richtungen ausbreiten, kann ein quantenmechanischer Agent alle möglichen Aktionen gleichzeitig erforschen. Dies nennt sich Superposition. Sobald wir aber eine Messung durchführen, also den Agenten fragen, welche Aktion er durchgeführt hat und ob er eine Belohnung erhalten hat, bricht diese Superposition zusammen. Der Trick ist also, nur zu geeigneten Zeiten zu messen und die quantenmechanische Suche nach Belohnungen sowie das klassische Messen und Verstärken optimal zu kombinieren.