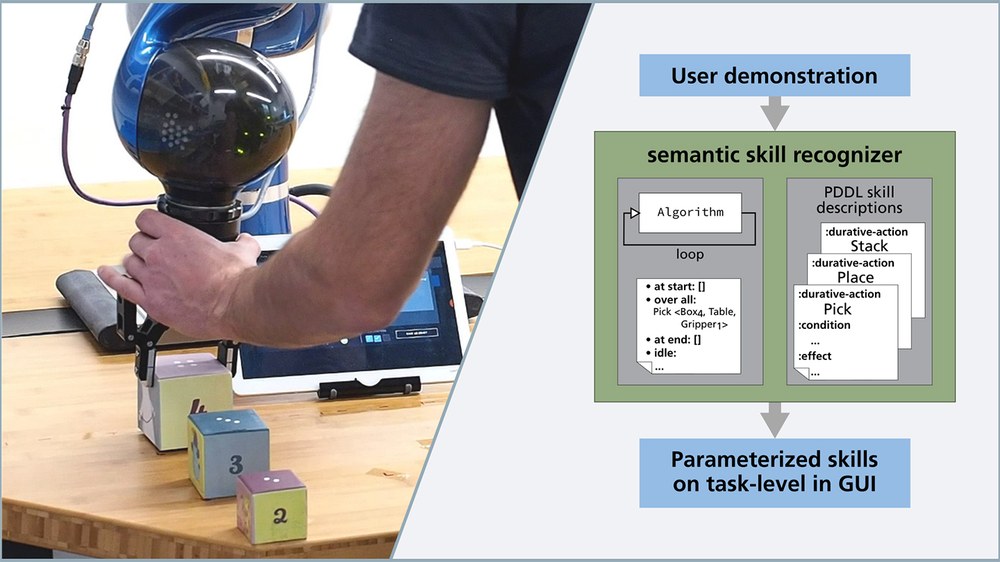
Programmieren eines Roboters auf Aufgabenebene mit einer Demonstration
Ausgestattet mit einer Reihe an Roboterfähigkeiten (Skills), die semantisch mit Bedingungen und Effekten annotiert sind, kann der Algorithmus zur semantischen Skillerkennung online während einer Demonstration die parametrisierten Fähigkeiten erkennen, die nötig sind, um die vorgemachte Aufgabe zu reproduzieren. Die so erstellte Abfolge an Skills wird in einer grafischen Benutzeroberfläche (GUI) dargestellt, in der diese inspiziert und modifiziert werden kann.
Datengesteuerte Ensemble-Vorhersage für fehlertolerante Posenschätzung
Fehlertolerante Sechs-DoF-Positionsschätzung für den DLR-Roboter DAVID. Mehrere Polynomschätzer werden mit strukturierten Verdeckungen der verfügbaren Sensorinformationen trainiert und auf Basis der verfügbaren Sensoren zu Ensembles geclustert. Durch Berechnung der Varianz eines Ensembles wird die Unsicherheit in der Vorhersage überwacht und wenn die Varianz über einem Schwellenwert liegt, wird ein Sensorverlust erkannt und behandelt.
Interaktives Lernen von Fertigkeiten ist eine Fachgruppe in der Abteilung Kognitive Robotik.
Viele Roboter sind allgemein einsetzbar, um eine Vielzahl von Aufgaben zu lösen. Aber sie können das in der Praxis nur, wenn sie eine Vielzahl von Fertigkeiten haben, um solche Aufgaben ausführen zu können. Fertigkeiten sind Roboterprogramme, die ihnen gewisse Fähigkeiten verleihen. Das Ziel der Gruppe „Interaktives Lernen von Fertigkeiten“ ist es, Methoden zu entwickeln, durch die Roboter schnell und effektiv neue Fertigkeiten erlangen, und zwar durch Nachahmung (Programming by Demonstration), Verstärkungslernen (reinforcement learning) und intuitives Programmieren.
Um den Erwerb der Fertigkeiten schnell und effektiv zu gestalten, gehen wir davon aus, dass Roboter in der Lage sein müssen, ihre Fertigkeiten durch eine Kombination aus Vorwissen und datengetriebenen Methoden zu lernen. Daher zielen wir darauf ab, Menschen mit unterschiedlichem Grad an Roboterexpertise in die Lage zu versetzen, ihr Wissen und ihre Erfahrung über Fertigkeiten und Aufgaben auf den Roboter zu übertragen. Beispielsweise entwickeln wir Methoden, mit denen Experten ihre Kenntnisse über Bedingungen der Aufgaben spezifizieren können, zum Beispiel "eine Tasse sollte gerade gehalten werden, wenn sie nicht leer ist". Diese Bedingungen werden als virtuelle Führungshilfen ("virtual fixtures"), geometrische Primitive oder Mannigfaltigkeiten dargestellt. Für Menschen ohne Expertise in der Robotik untersuchen wir Methoden, die es erlauben, solche Randbedingungen aus Demonstrationen zu extrahieren und über ein intuitives grafisches Interface zu beschreiben. Solche expliziten Bedingungen lassen sich besser auf neue Aufgaben oder andere Roboter übertragen als das statistische Modelle alleine können.
Wenn Roboter einmal Fertigkeiten erworben haben, sollten sie diese Fertigkeiten im Laufe der Zeit verbessern und zwar hinsichtlich Geschwindigkeit, Energieeffizienz und Robustheit. Dazu verwenden wir Black-Box-Optimierung und Verstärkungslernen (reinforcement learning). Eine wichtige Grundlage unserer Forschung ist, dass Lernen und Exploration zielgerichtet sind, d. h. der Suchraum wird effizient durchsucht aufgrund von Vorwissen, welches wiederum von Menschen vorgegeben wird. Da Menschen ihren gesunden Menschenverstand und viel Vorwissen über die Lösung von Aufgaben einbringen können, erachten wir es als nicht sinnvoll, Roboter ohne jegliche Vorkenntnisse lernen zu lassen. Was schon bekannt ist, muss nicht noch mal erlernt werden.
Menschen verstehen es besonders gut, große Aufgaben in kleinere Teilaufgaben zu zerlegen. Um dieses Wissen zu übertragen, stellen wir intuitive grafische Werkzeuge zur Programmierung von Fertigkeiten und Aufgaben zur Verfügung. Diese Werkzeuge werden verwendet, um Fertigkeiten anzulegen, Aufgaben zu definieren und das System während der Ausführung zu observieren. Die Herausforderungen hierbei sind, das System transparent zu machen, ein konsistentes mentales Modell zu finden, die Selbstbeschreibungsfähigkeit zu erhöhen und den Aufwand zu reduzieren. Unterschiedliche Interaktionsstrategien werden dabei zielgerichtet und den Nutzerpräferenzen entsprechend integriert. Ein dynamisch veränderbarer Grad an Autonomie soll die Nutzerakzeptanz erhöhen. Das wird durch die Erkennung der Benutzerintention und ein kontinuierliches Feedback des Systems unterstützt.



{kind=link}
{kind=link}